Apache Kafka
山海鲸可视化,提供一站式数字孪生解决方案,致力于打造一款人人都会用的,零代码数字孪生工具。
简介
Apache Kafka 是一个开源的流式数据平台,由 Scala 写成。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。

适用场景
Apache Kafka 适用于数据集成、日志聚合、实时数据处理、事件驱动架构、大数据集成、监控警报、分布式系统通信和云原生架构等多种场景。它提供高吞吐量、持久性、实时数据流传输,用于构建实时数据管道、日志管理和实时应用程序,适应各种大数据处理需求。
优势: Apache Kafka 的优点在于其高吞吐量、持久性、实时性、可扩展性和数据集成能力。它可用于构建大规模数据管道和实时应用程序,适应多种场景。
缺点:Kafka 的配置和维护可能复杂,需要专业知识。对于小规模应用,可能会过于复杂。另外,确保数据一致性和可靠性可能会引入一些延迟。
图例
- Apache kafka 安装后的二进制包。

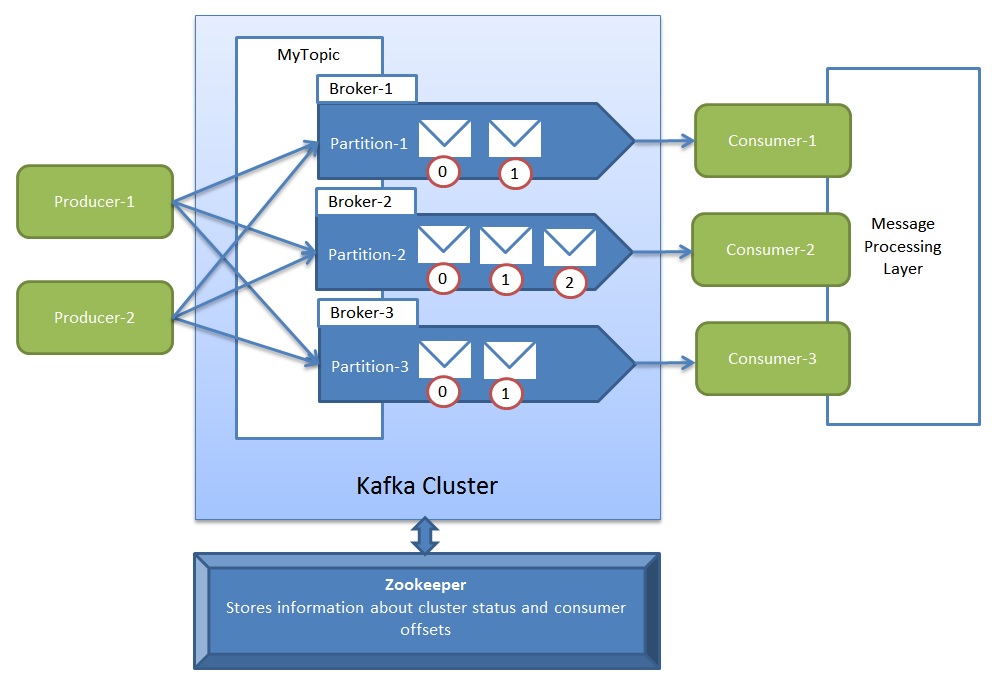
- Apache kafka结构。
数字孪生大屏应用案例
目前,我们山海鲸可视化资源中心提供了丰富的数字孪生大屏案例,在网页上就可以快速体验大屏。



相关数据源
参考资料